
티스토리 뷰
챕터 2의 두번째...43쪽이다 되네 ㅠㅠ
리뷰 시작!
1/43
2.9 Learning without a teacher
- teacher가 없다는 것은 NN이 학습하는데 예제에 대한 label이 없다는 것이다.
- 2가지 방법이 있다 : reinforcement learning이나 neurodynamic programming and unsupervised learning
- (1) reinforcement learning : 입출력 매핑으로 환경과의 지속적인 상호작용을 통하는 learning으로 scalar index를 최소화 함으로써 성능을 개선하는 것
- Fig 2.7은 한가지 'critic' 이 'primary reinforcement signal'을 'heuristic reinforcement signal'로 바꾸는 것을 보여주고 있다.
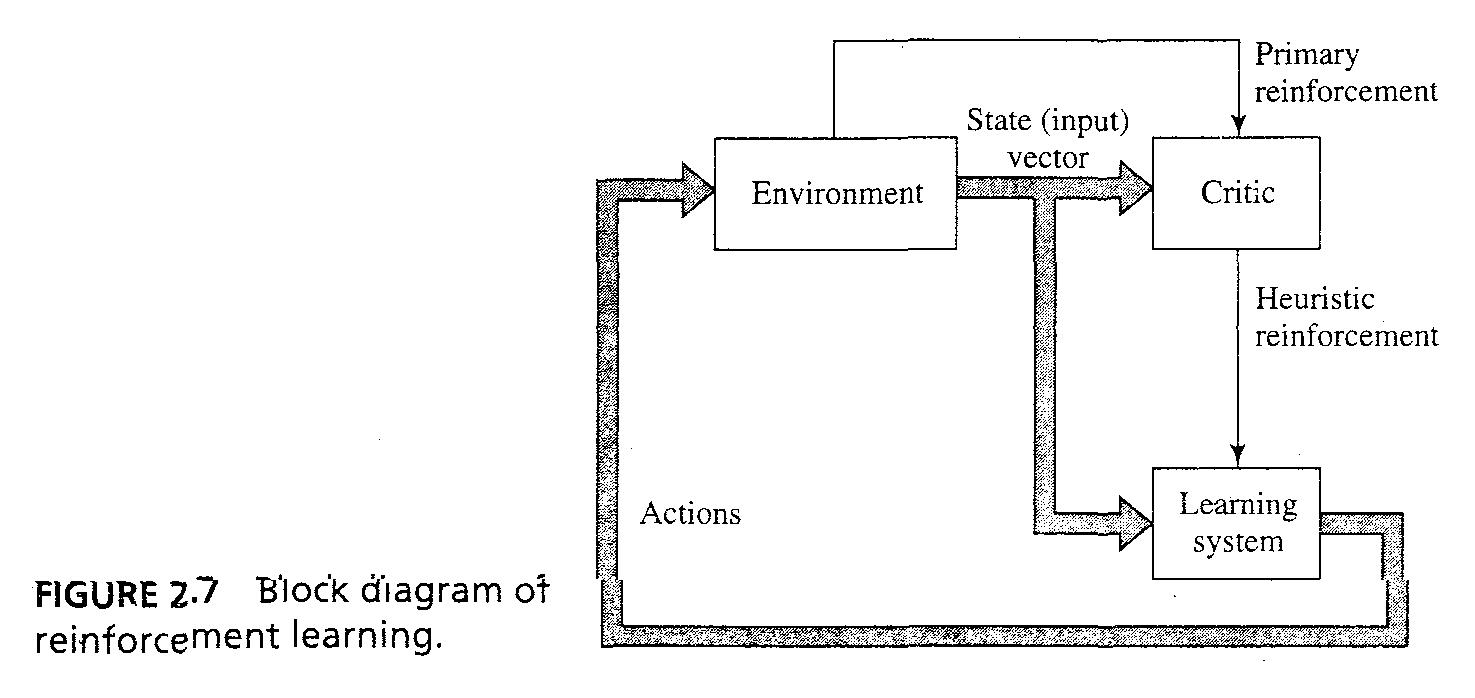
3/43
- 시스템은 delayed reinforcement를 기반으로 배우도록 디자인 되었다.
- learning의 목표는 actions에 대한 시퀀스의 단계를 지나며 점증적인 cost의 expectation하는 'cost-to-go function'을 최소화하는 것이다.
- Learning machine의 기능은 이 action들을 discover하는 것이고, 그것이 어려운 이유는 2가지가 있다. (1) no teacher provides feedback, (2) delay 때문에 machine이 temporal CAP를 해결해야하는 것을 뜻한다.
4/43
- 따라서 어렵다. 환경과의 상호작용을 통해서 상호작용후의 경험의 결과로 배우는 능력을 발전 시키는 기본을 제공한다.
- Reinforcement learning은 dynamic programming과 optimal control theory안에서 가깝다. 순차적인 결정에 대한 수학적인 규정을 제공하는 것에서..
5/43
- (2) Unsupervise learning : unsupervised learning이나 self-organized learning에서 teacher나 critic 없어서 전체 learning process를 oversee하지 못한다. Fig 2.8에서 처럼..
- provision은 학습의 표현의 성능에 대한 'task independent measure'이고 NN의 free parameters는 이 값에 대하여 최적화 되어있다.
- 한때 NN이 입력데이터에 대하여 확률적으로 평범하게 튜닝되면, 그것은 새로운 class를 분류하기 위해 내부 representation을 형성한다.
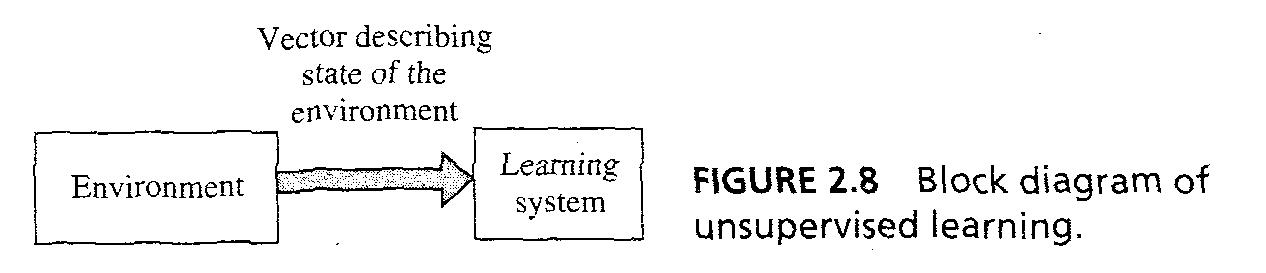
7/43
- 예를 들면, NN이 입력과 competitive 레이어를 가지고 있으면, 입력 레이어는 가용한 데이터를 받게 되고, competitive layer에 있는 뉴런들은 서로 compete해서 (learning rule에 기반해서) 입력 데이터에 포함된 feature에 대하여 'winner-takes-all' 전략에 반응할 'opportunity'를 잡으려고 한다.
8/43
2.10 Learning task
- learning algorithm을 선택하는 것은 NN이 요구하는 learning task 에 따라 변화된다. 6가지 learning task가 있다.
- Pattern Associations : 'association'은 Aristotle이후 인간 기억의 가장 prominent한 feature로 알려졌고, cognition의 모든 모델은 association을 활용한다.
* ssociation은 두가지 form이 있다 : 'autoassociation'과 'heteroassociation'
9/43
- autoassociation에서 NN은 입력 패턴을 저장하였다가 나중에 같은 패턴의 집합이 나오면 retrieve하고, heteroassociation은 arbitrary input pattern이 arbitrary output pattern과 짝지어진다.
- autoassociation은 unsupervised learning을 포함하고 heteroassociation은 supervised learning을 포함한다.
10/43
- 'key pattern vector' x_k와 memorized pattern vector y_k, 패턴 association은 x_k->y_k로 묘사된다 ... 2.18
- autoassociative memory y_k = x_k이고 heteroassociative memory에서는 y_k<>x_k이다.
- associative 메모리는 두가지 phase가 있다 : 'storage phase' for training NN, 'recall phase' for 기억된 패턴을 retrieval하는 phase
- Fig 2.9가 블록 다이어그램이다.

12/43
- Pattern Recognition
- PR은 일반적으로 'the process whereby a received pattern/signal is assigned to one of prescribed number of classes(categories)'
- NN을 통한 자연상태의 PR의 perform은 다차원의 decision space에서 패턴은 점들로 나타낸다.
- Decision boundaries는 training으로 정의된다.
13/43
- NN을 통한 PR machine은 2가지 form중 하나를 가진다 : (1) machine은 두가지 part를 가진다, unsupervised network에서의 'feature extraction'과 supervised network에서의 classification을 가진다. Fig 2.10a처럼..
- (1) traditional PR approach에서, 패턴은 m차원의 'observation (data) space'에서 점 x로 나타낸다. feature extraction은 점 x을 q차원의 feature space 상에서의 점 y로 바꾼다. q < m
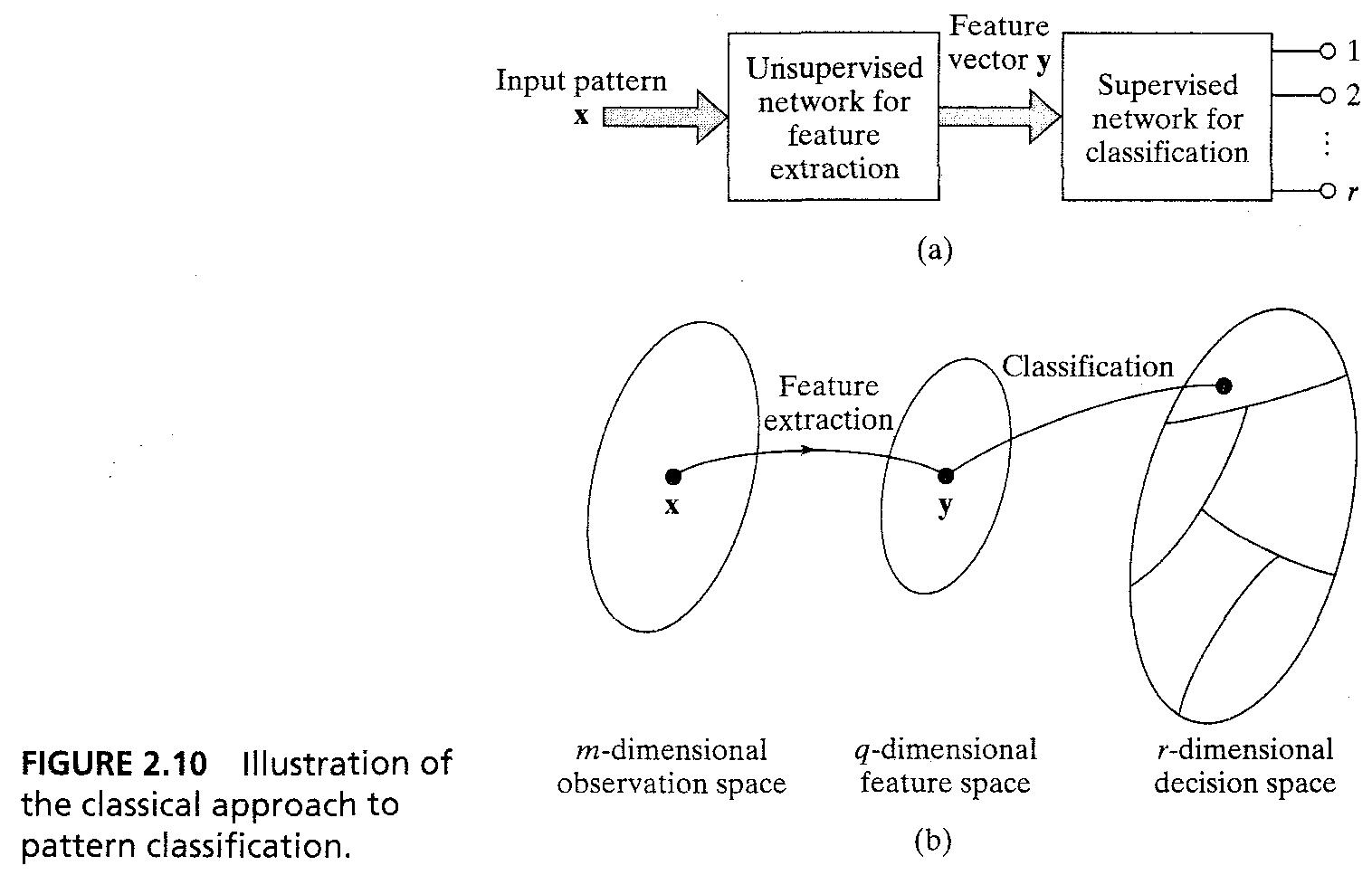
15/43
- 분류는 y를 decision space위의 한 점으로 바꾸는 것을 뜻한다.
* (2) 두번째 종류는 multilayer feed forward network using supervised learning이고, feature extraction은 hidden layer에서 이루어 진다.
16/43
- Function approximation
- non-linear 입출력 매팅은 d = f(x) ... 2.19 로 묘사, 함수 f는 알수 없음
- labeled examples T = {(x_i , d_i)}_i, f(.)을 묘사하는 NN을 설계, such that 입출력 매핑이 모든 입력에 대해서 충분히 가까울 수 있도록, ||F(x)-f(x)|| < ε ... 2.21
- Approximation problem은 supervised learning의 완벽한 후보이다. x_i는 입력벡터이고, d_i는 원하는 결과이다.
17/43
- supervised learning을 approximation problem으로 볼 수 있다, NN의 approximate 하는 능력은 2가지로 묘사된다 : system identification과 inverse problem
- System identification : 2.19 등식이 입출력의 관계를 묘사하는 것이다. 시간 불변하는 알 수 없는 메모리 없는 MIMO(multi input multi output) system에서 의 입출력 관계..
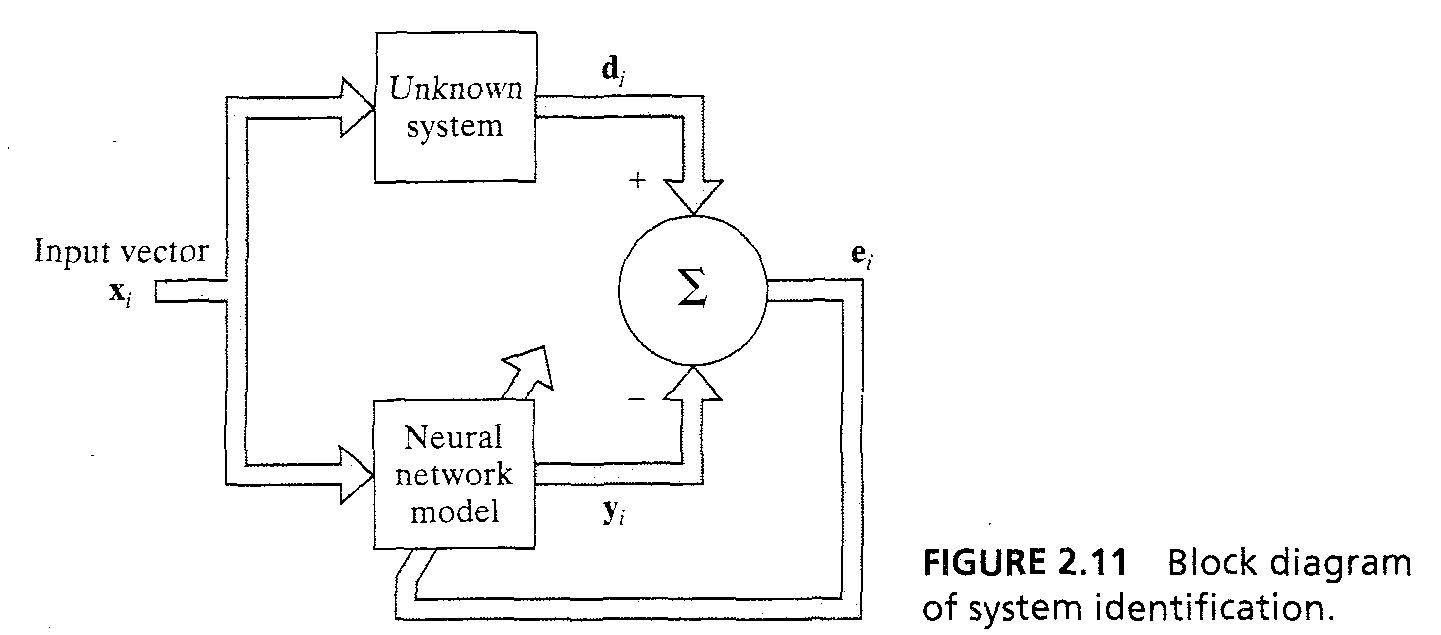
19/43
- inverse system : 같은 memoryless MIMO system이 2.19 등호 처럼주어지면 문제는 입력 d에 대하여 x를 뽑아내는 inverse system을 설계하는 것이다.
- 우리는 f^-1(.)을 통해 NN approximation을 설계할 수 있다. Fig 2.12의 scheme을 활용해서..
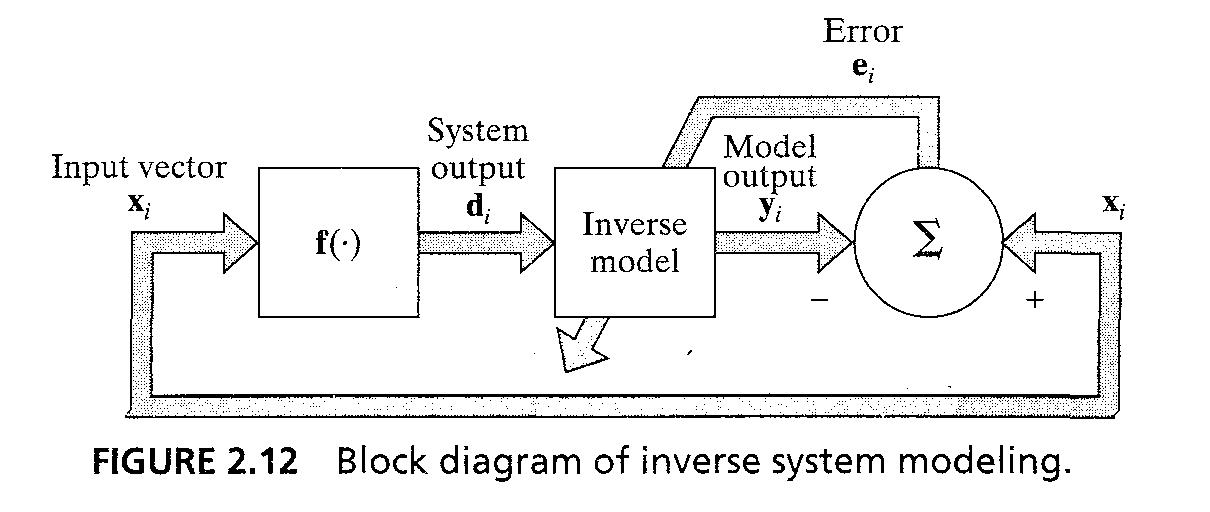
21/43
- Control
- fig 2.13의 feedback control system을 고려, 출력 y가 reference signal d를 뺀 일정한 feedback이 사용된다.
- NN controller의 목적은 plant에 알맞는 입력을 넣어서 출력 y가 reference signal d를 track하도록 하는 것이다. controller는 invert plant의 입출력 특성을 가진다.
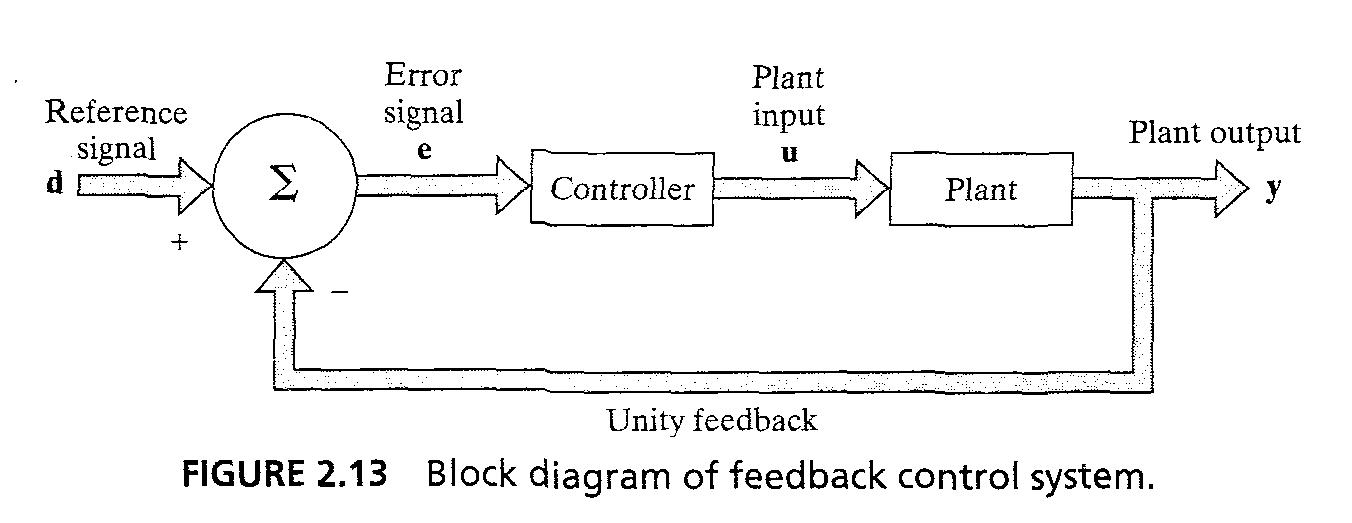
23/43
- 잘 알 수 없는 Jacobian matrix J = {∂y_k/∂u)i} 를 찾아야한다
- 두가지 접근방법이 있다. indirect learning, direct learning
24/43
- (2) 'smoothing' 시간 n 까지 데이터를 사용해서 정보를 extract함
- (3) 'prediction'을 해서 시간 n+n_0의 미래에 있는 정보를 현재 n_0에 있는 데이터를 가지고 derive하는 것
- filtering problem의 예 : 'cocktail party problem' 한 background sound와 speechs 속에서 한 spearker의 speech에 집중하는 능력
- NN에서는 'blind signal separation'이 유사하다
25/43
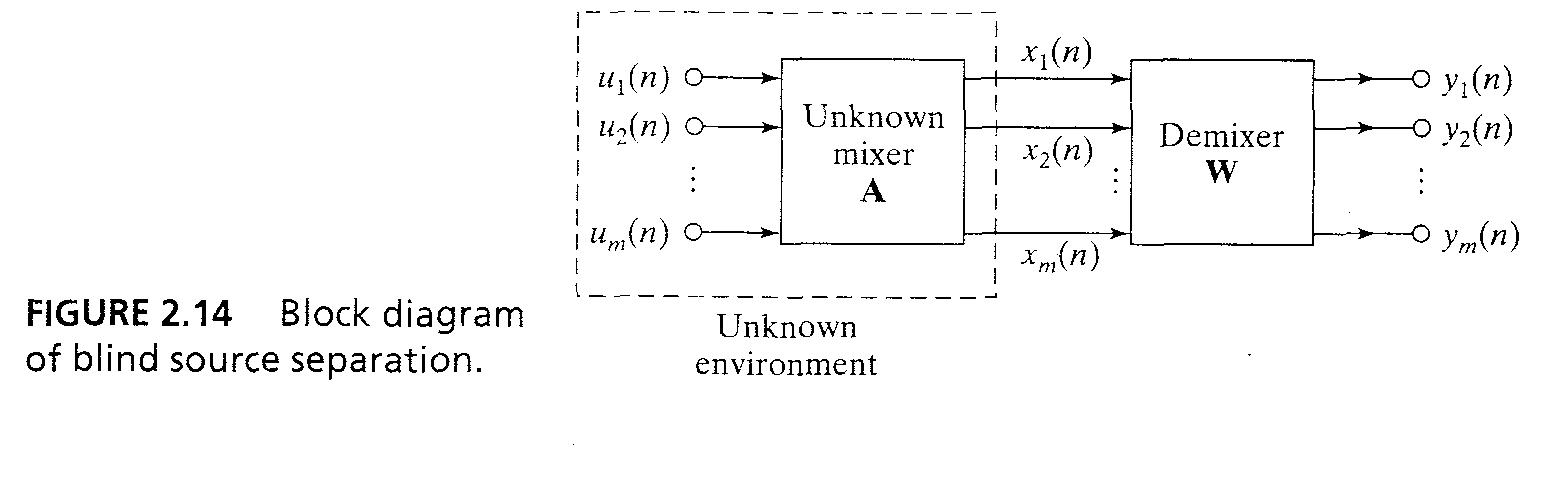
- 알수 없는 source signal {s_i(n)}의 서로 독립적인 집합이 있으면, fig 2.14처럼 linearly mix 되어서 m-by-1 observation vector x(n) = Au(n) ...(2.24)를 생성한다. A는 unknown non-singular mixning matrix.
- 주어진 관측 벡터 x(n), 조건은 original signal을 unsupervised한 방법으로 복구하는 것이다.
- Prediction은 error correction learning을 통해 해결 될 수 있다. unsupervised manner fig 2.15를 통해..
- prediction 는 model building이라고 봐도 된다
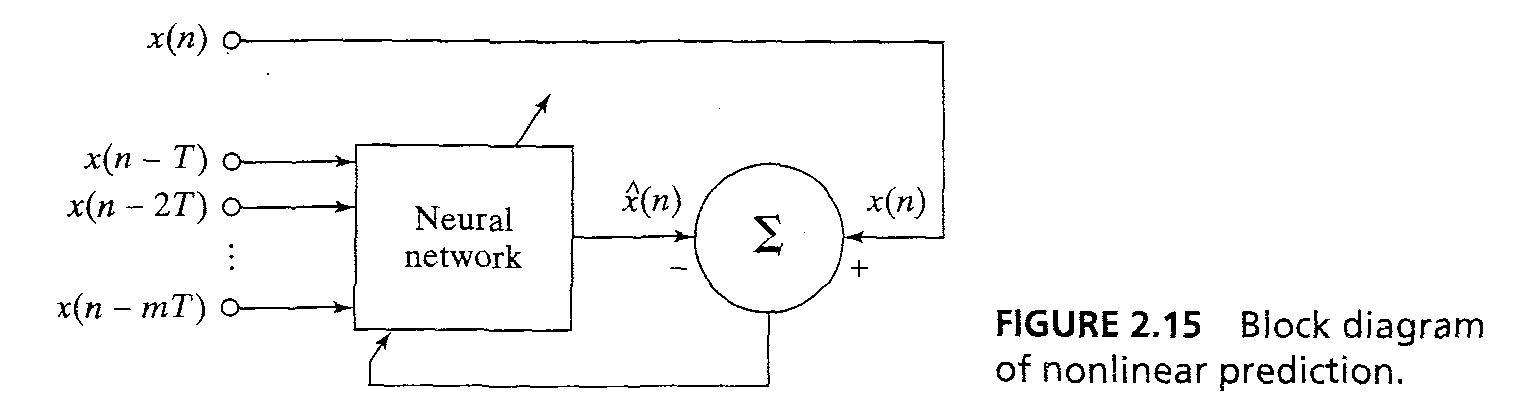
29/43
2.11 Memory
- memory는 뉴럴의 변화가 유기적인 환경과의 지속적인 상호작용으로 일어나는 것을 말한다.
- 'accessible'해야하고, 처음엔 learning process를 통해서 'stored'되어야한다.
- Short term memory 는환경에 대한 현재 상태의 knowledge에 기반하고 long term memory는 오랜 시간 또는 꾸준히 저장된 knowledge에기반한다
30/43
* associative memory의 특징을 공부한다 : distributed; stimulus pattern and response pattern are data vectors; info is stored as spatial pattern of neural activities; resistance to noise and damage; interactions between individual stored patterns.
- distributed mapping, 패턴을 입력 space에서 output space에 있는 activity pattern로 바꾸는 것.
- Fig 2.17a는 model component of nervous system과 b ANN을 보여준다.
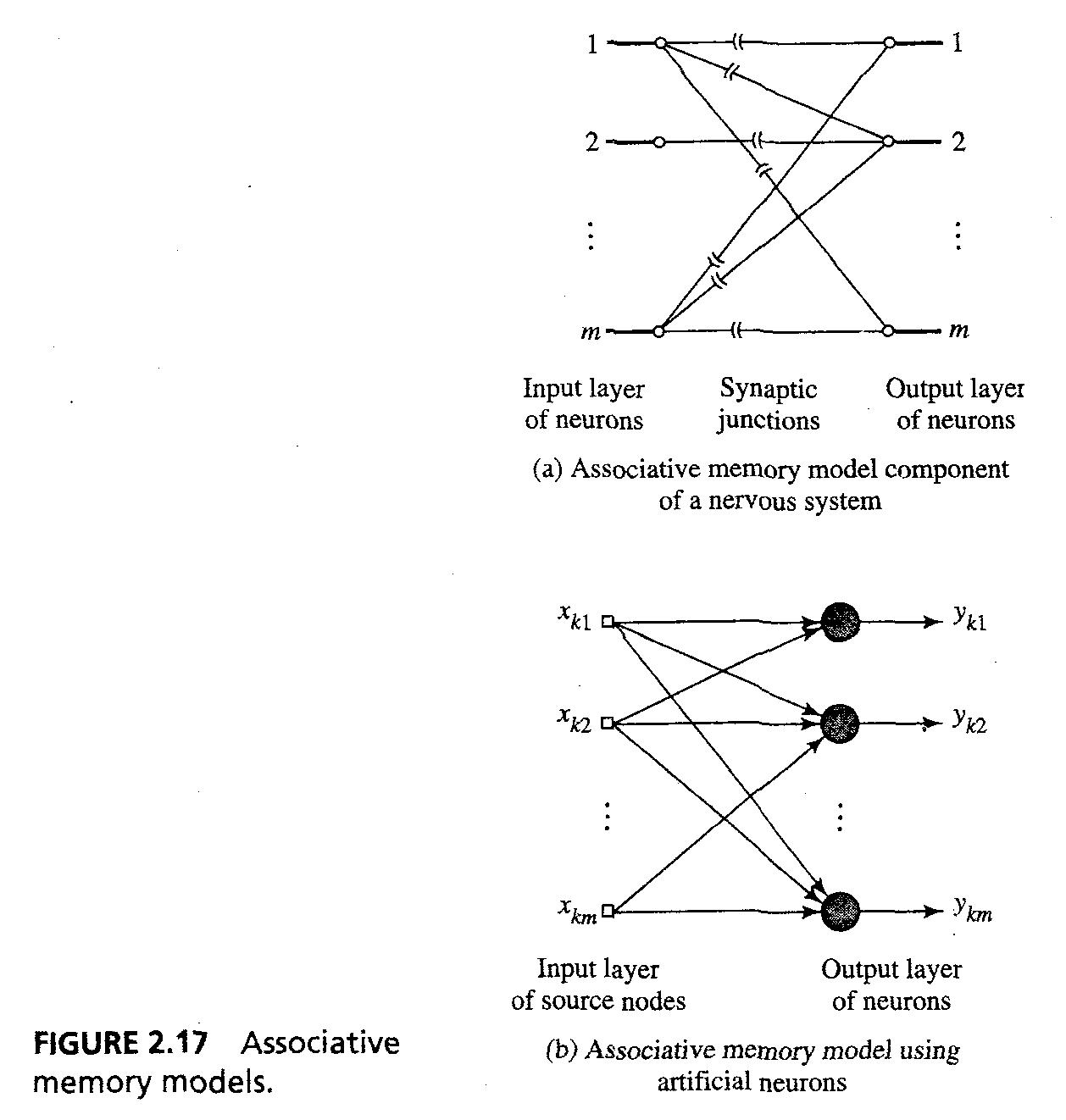
32/43
- Fig 2.17a,b에 있는 NN이 다음의 analysis로 linear라고 하면, Fig2.18에서 neuron acts as linear combiner.
- 패턴 x_k와 y_k는 벡터로 나타낸다. "m"은 네트워크의 차원수이다
- association of key vector x_k와 저장된 y_k는 y_k=W(k)x_k ... 2.27로 나타낸다. W(k)는 입출력 쌍 (x_k, y_k)에 대한 weight matrix이다.
33/43
- 출력 y_ki는 뉴런i와 패턴 x_k는 y_ki = sum_j(w_ij(k)x_kj)로 wij는 뉴런 i의 k번째 associated pattern 쌍에 대한 synaptic weights이다.
- m-by-m memory matrix를 전체 집합의 pattern association에 대한 weight matrices의 총합이라고 정의 : M = sum(W(k)) ... 2.32, M_k = M_k-1 + W(k) ... 2.33 으로 재 정의 된다.
34/43
2.11 Memory correlation matrix memory
- M^ = sum_k(y_kx_k^T) ... 2.34 는 estimate memory matrix M을 나타낸다. term y_kx_k^T는 outer product를 나타내고 키 패턴 x_k와 memorized pattern y_k이다.
- 등식 2.34는 generalization of Hebb's postulate of learning 이라고 볼 수도 있다, outer product rules이라고도 알려졌다.
- Association memory는 correlation matrix memory로 불리운다.
* correlation은 한편으로는 learning, association, PR과 memory recall in human nervous system의 basis이다.
35/43
- M^ = YX^T
- matrix X는 키 패턴으로 조합된 m-by-q matrix이고, learning called key matrix에서 활용되고, Y는 memorized patterns으로 조합된 m-by-q matrix이고 memorized matrix이라고 불린다.
- 등식 2.35는 재귀적으로 다음과 같이 재정의 된다. M^_k = M^_k-1 + y_kx_k^T... 2.38
- 신호 흐름 그래프는 fig 2.19처럼 나타낼 수 있다.
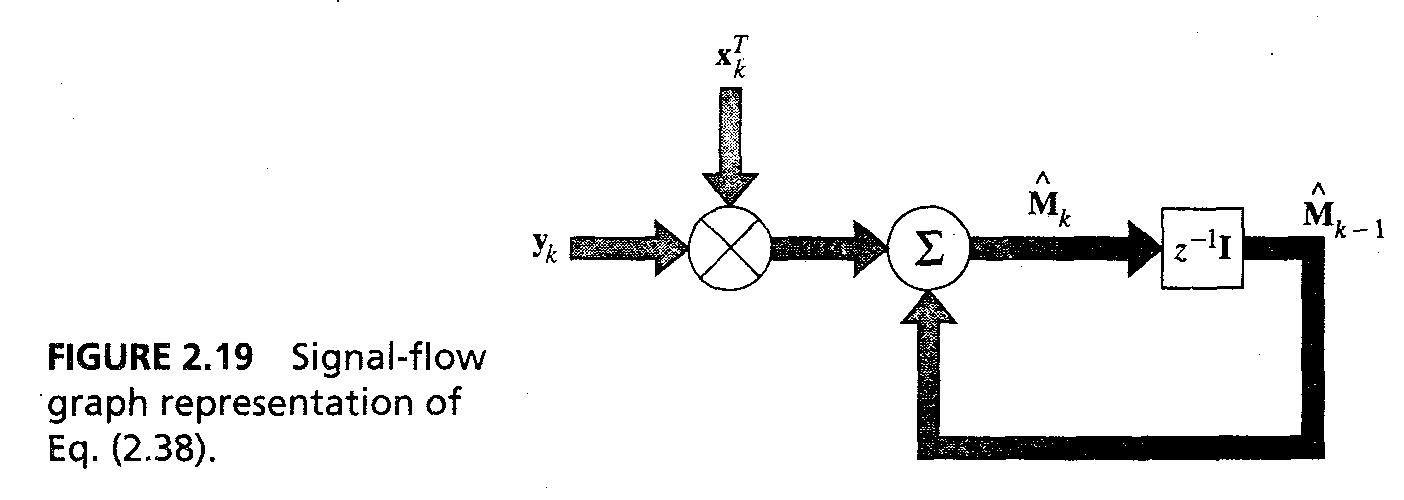
37/43
2.11 Memory recall
- 키 패턴 x_j와 memory yielding response y = M^x_j, y = sum(y_kx_k^Tx_j) = sum(x_k^Tx_j)y_k ... 2.39~2.40
- x_k^Tx_j는 키 벡터 x_k와 x_j의 inner product이고, y=(x_j^Tx_j)y + sum(x_k^Tx_j)y_k ...2.41 where k<>j
- 키 패턴들이 unit energy를 가지도록 normalize 시킨다.
38/43
- y = y_j + v_j ... 2.43이라고 쓸 수 있다. y_j는 'desired response'이고 v_j는 'noise vector'이다. 'crosstalk'에서 키 벡터 x_j와 다른 memory상의 키벡터 사이에서 일어난다.
- v_j=sum(cos(x_k,x_j)y_k), 키 벡터가 orthogonal하다면 cos(xj,xj)=0, k<>j일 때... 2.49
- memory associates perfectly, 만약 키 벡터가 orthonormal set, x_j^Tx_j = 1, 만약 k=j이고 나머지일 때에는 0
39/43
- 저장된 패턴의 수는 input space dimensionality를 넘지 못한다.
- real life에서 key patterns는 orthogonal하지도 않고 seperable하지도 않다.
40/43
2.12 Adaptation
- 동물들은 temporal 구조에 특정한 behavioral space에서 이벤트에 대해 그 행동을 adapt한다.
- 만약 환경이 정지해 있다면, 'freeze' memory에 의해 학습 될 수 있고, 필용할 때 다시 호출 될 수 있다.
- 만약 환경이 nonstationary하다면 supervised learning은 inadequate할 수 있다.
- 계속 적인 input signal에 대한 free parameter들의 adapt는 'continuous learning' 또는 learning on the fly 라고 한다.
41/43
- linear adaptive filter는 linear combiner 주변에 만들어지고, continuous learning을 perform하기 위해 디자인 된다.
- 이 변화를 addressing하는 방법은 non-stationary process의 통계학적인 특징을 인식하는 것이다. 이 process는 보통 pseudo-stationary라고 할 정도로 짧은 duration의 윈도우를 통해서 천천히 변한다.
42/43
- 예 : 날씨 정보는 시간을 통해 stationary이다. 주식 시장은 하루 동안 stationary하다
- 우리는 NN을 특정한 시간 간격별로 retraining해서 입력 데이터에 대한 끊임없는 통계적인 변화에 대응할 수 있다.
- 더 좋은 dynamic approach to learning은 : short enough window; update window upon reception of new data를 통해서 가능하다.
43/43
* NN은 time-ordered examples를 활용한 coninual training을 따르고, nonlinear adaptive filter 일반적인 linear adaptive filter로 만든다.
- 한 샘플링 기간 동안 리소스는 그 안에 계산을 완료할수 있도록 충분히 빨라야 한다.
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
TAG
- 강좌
- php
- c++
- TIP
- Python
- Android
- gae
- 서울
- Javascript
- 사진
- 팁
- ny-school
- 탐론 17-50
- 자바스크립트
- 안드로이드 앱 개발 기초
- java
- Writing
- HTML5 튜토리얼
- mini project
- 삼식이
- 뽐뿌
- K100D
- 샷
- lecture
- gre
- google app engine
- HTML5
- 속깊은 자바스크립트 강좌
- GX-10
- 안드로이드
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
글 보관함